
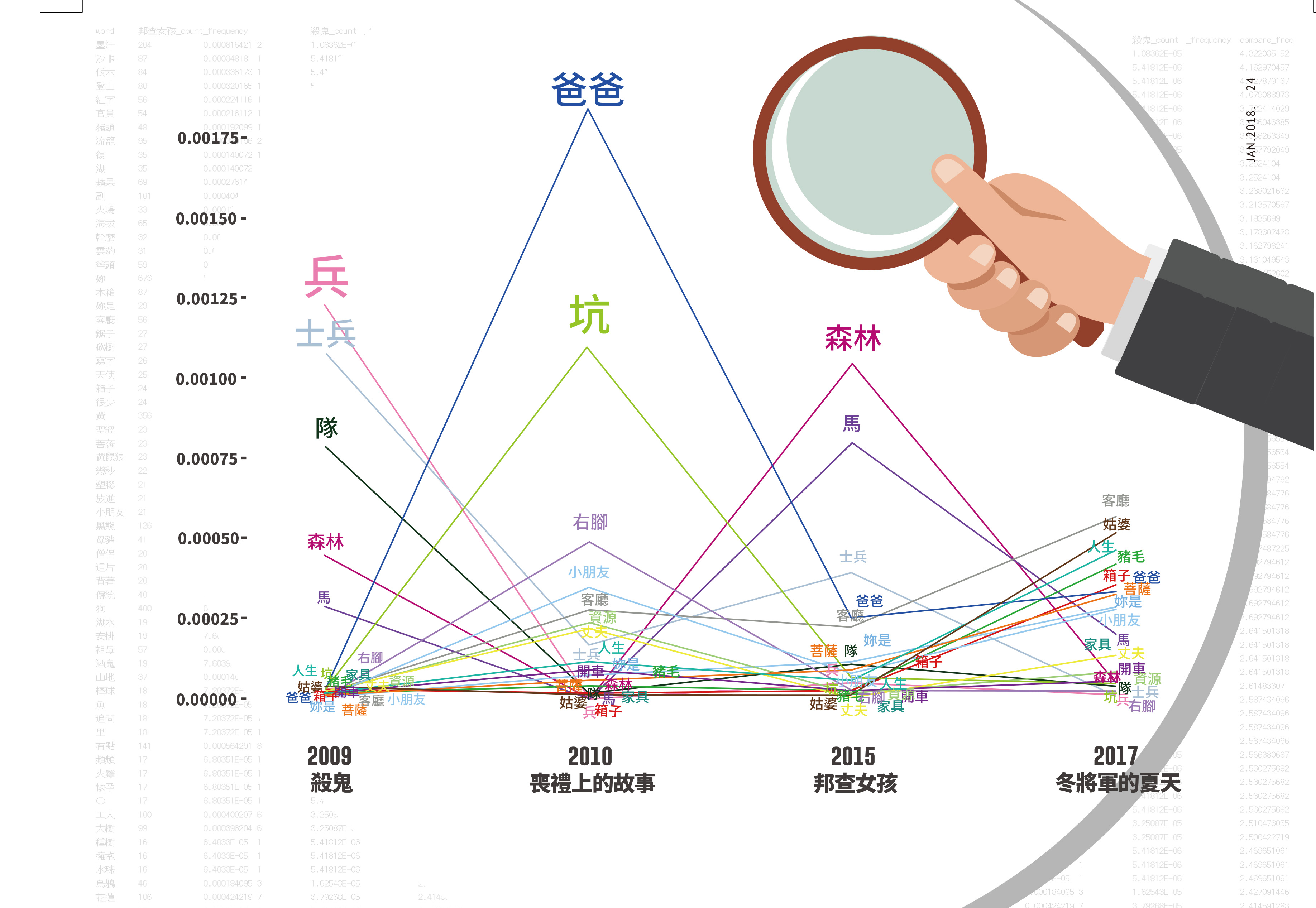
這次進行小說家甘耀明的作品分析,主要的手段是透過開源工具Jieba分詞工具來進行。雖然 Viterbi 演算法尚不能成功識別出某些精妙奇詭的用詞,但透過機率路徑完成的分詞手段有別於 n-gram 演算法,可以更容易找出「只在文本中出現一次的詞」,所以此次文本風格分析的目標,就是利用新的工具特性找出小說家甘耀明的長篇小說作品風格用詞偏好差異。小說家揀選的用詞,暗示他對該詞的質感、語感、意象上的偏好,如果能觀察到小說家用詞傾向的改變,也許就能揣測出小說家藝術經營策略的變化。值得一提的是,各本小說分詞出現次數的中位數皆為1,代表超過半數的詞種都只出現一次,由此可以看到資料零碎分散的程度。為了直接呈現視覺上有意義的資料,筆者搜尋出四本小說皆有使用過的詞,並且在找出該詞在各本小說的詞頻之後,將其最大值除以最小值,以求出使用頻率在四篇作品中有明顯起伏的詞。這就是圖表上所呈現的,「變化幅度最明顯的共用詞Top 20」。
《喪禮上的故事》
分詞種類數量:11485
平均出現次數:4.1
標準差 :32.9
《冬將軍的夏天》
分詞種類數量:14055
平均出現次數:5.2
標準差 :48.1
《殺鬼》
分詞種類數量:28734
平均出現次數:5.6
標準差 :68.9
《查邦女孩》
分詞種類數量:32124
平均出現次數:6.9
標準差 :94.3
•標準差
標準差數值越高,代表字詞出現次數越分散。
亦即,大部分詞的出現次數都與平均值有段距離。
•詞頻
單詞出現次數,除以單本小說的總詞數。
•中位數
中位數是統計數字從小排到大,位於正中間的數字。中位數是1,且平均值大於1的情況,代表小說中絕大多數的詞,都只出現一次。
李奕樵
一九八七年生。全人實驗中學肄業。高雄中學畢業。耕莘青年寫作會成員。秘密讀者成員。曾獲林榮三文學獎小說獎二獎,入選九歌一○二年小說選。撰寫軟體維生。短篇小說集即將集結出版。
◆本文原刊載於《聯合文學》第399期